
Many pump failure statistics compiled inside refineries and petrochemical plants point to mechanical seals as the pump system component that fails most frequently. The engineers and technicians assembling these data usually choose to stay silent. Regrettably, their plant managers often believe they have an unspecified competitive advantage by not releasing the data. Consulting engineers sign confidentiality agreements. Current American Petroleum Institute (API) standards, however, have enabled the hydrocarbon processing and other industries to take large leaps in reliability improvement and downtime avoidance. For decades, these API standards have contained seal flush plans that allow users to specify and manufacturers to offer seal support systems that suit the specific requirements of a particular pumping service.
 Image 1. A CPRS engineer investigates pump upgrading opportunities (Courtesy of Hydro Middle East, Technopark, Dubai, UAE)
Image 1. A CPRS engineer investigates pump upgrading opportunities (Courtesy of Hydro Middle East, Technopark, Dubai, UAE) Figure 1. An innovative mechanical seal (left) incorporating a bi-directional tapered pumping device (right). (Courtesy of AESSEAL Rotherham, UK, and Knoxville, Tennessee, USA)
Figure 1. An innovative mechanical seal (left) incorporating a bi-directional tapered pumping device (right). (Courtesy of AESSEAL Rotherham, UK, and Knoxville, Tennessee, USA)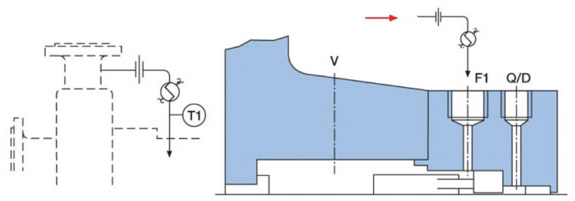 Figure 2. Seal Flush Plan 21—product recirculation from discharge through orifice and heat exchanger (Courtesy of AESSEAL)
Figure 2. Seal Flush Plan 21—product recirculation from discharge through orifice and heat exchanger (Courtesy of AESSEAL)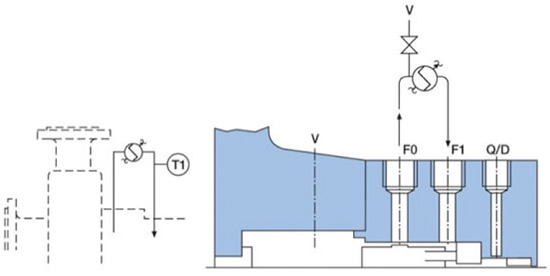 Figure 3. Seal Flush Plan 23—product recirculation from seal chamber through heat exchanger and back to seal chamber (Courtesy of AESSEAL)
Figure 3. Seal Flush Plan 23—product recirculation from seal chamber through heat exchanger and back to seal chamber (Courtesy of AESSEAL)A Management Critique
Equipment failures that could be avoided often persist because of human error. Plants lack the investment in education, personnel, tools and time necessary for preventing these mistakes. Large-scale investments in predictive maintenance devices and tools are often left idle or cannot be used because plant staff members have not been trained, mentored or taught to interpret data. For example, many end users who use computerized maintenance management systems (CMMS) are still reporting inadequate information such as "bearing replaced," "bearing failed" or "bearing repaired" instead of "bearing failed because of loose oil ring abraded, and brass chips contaminated the lube oil. Corrections made by upgrading to a clamped-on flinger disc." Facilities must practice failure analysis by taking remedial action instead of merely replacing parts. People in authority often make wrong decisions. As an example, they require employees to standardize on just one type of lubricant, to buy critical machinery and components from the lowest bidder, to procure replacement parts without linking them to a well-thought-out specification, or to stock parts without first thoroughly inspecting them for dimensional and material-related accuracy or specification compliance. Random failures demand that good options be readily available. Reliability engineers often try to make their responsible supply chain staff or purchasing departments understand that it is impossible for the maintenance department to plan and accurately predict spare parts demand. This is because a major proportion of equipment and systems fail randomly. A good example of parts that should be readily available is rolling element bearings in all industries worldwide. According to a bearing manufacturer's statistics, 91 percent of bearings fail before they reach the end of their conservatively estimated design lives. Only 9 percent reach the end of design life. The millions that prematurely fail each year can all be slotted in one or more of the seven basic failure categories:- operator error
- design oversights
- maintenance mistakes
- fabrication/processing defects
- assembly/installation error
- material defects
- operation under unintended conditions
- 25 percent of all failures are preventable but not prevented.
- 15 percent of all failures are predictable but not predicted.
- 20 percent of all failures are predicted but not acted upon to undertake repair.
- 25 percent of all failures are predicted, with machines stopped to do repairs.
- 15 percent of all failures are neither preventable nor predictable.
- 25 percent of all failures are preventable but not prevented because of arbitrary decisions that are simply not rooted in knowledge and experience. For example, "use the cheap oil" may overlook the fact that the cheap oil lacks demulsifiers or anti-foaming agents.
- 15 percent of all failures are predictable but not predicted. For example, the random appearance of "black oil" is attributable to O-ring degradation of a certain style of bearing protector seal. The bearings will soon fail, but nobody has read the books and articles that describe the occurrence. (The occurrence should be linked to a certain risky design feature on a widely used product.)
- 20 percent of all failures are predicted, but operation is not stopped to undertake repair. Chances are that someone in authority overruled an expert who asked for a shutdown when vibration increased beyond a safe level.
- 25 percent of all failures are predicted, and equipment is shut down for repair. While this is good, the organization's energy is funneled into restorative maintenance efforts instead of proactive upgrade efforts that would prevent failures in the first place. Prevention is better than spending money for restoration.
- Only an estimated 1 percent of all failures are neither preventable nor predictable. As of 2010, this number was updated. Humans make the decision to build cities in earthquake zones—either with suitable building codes or by disregarding them. Strong levies can be built or not built, maintained or not. Still, some machines might fail because a neighboring pressure vessel exploded or a fire in another unit spreads. These may indeed fit the estimated "neither preventable nor predictable" 1 percent category. The remaining estimated 14 percent belong in the other categories.
