
Adding condition monitoring and predictive maintenance for legacy or aftermarket industrial pumps and equipment is touted today as a significant source of return on investment (ROI) for the industrial internet of things (IIoT). For some, predictive maintenance is a new term, one many confuse with condition monitoring. The main difference in predictive maintenance and condition monitoring is the timing. While both monitor the health and condition of a rotating asset like a pump, fan, compressor, mixer, agitator, conveyor, etc., condition monitoring focuses on here-and-now conditions. Predictive maintenance focuses on the early detection of defects, 60 or 90 days before the defect causes collateral damage or impacts production. Here is information highlighting the history and transgression of condition monitoring.
Condition Monitoring 1.0—the 1980s & Earlier
Much like the red alerts on the dash of your car, legacy condition monitoring in industry has included lagging indicators such as:- low lube oil pressure
- high temperature
- low or high pump discharge pressure
- low or high seal pressure
- low or high seal pot level
Condition Monitoring 2.0—the 1990s to 2000s
A second wave of measurements has been adopted and has dramatically improved the detection of defects. Motor current, speed and power are the results of variable speed drives that have been deployed to improve efficiencies in electrical energy consumption. Additional vibration and bearing temperature measurements are more reachable thanks to cost reductions, reliability improvement, input/ output systems infrastructure and easy magnetic or epoxy mounting of sensors. This second wave of measurements includes motor current, speed, power, overall vibration and bearing temperature. A variance in any of these measurements can indicate a condition of the pump or pumping system that needs attention. Using these measurements has proved fruitful for diagnosing problems, but setting the alert thresholds for use with automated alerting has proved challenging. The varying nature of the process, product recipe or season of the year has made nuisance alarms common and has challenged the simplicity and clarity of the approach, thus requiring in-house or third-party expertise to realize success. Motor current, flow and pressure can vary with process conditions and require human analysis to identify a fault or anomaly in the normally varying measurements. One example is distinguishing a normal inrush current from an abnormal high current during steady state operations. Novice users have tried to baseline and set statistical alerts. Unfortunately with traditional methods and systems, this can be time consuming and has resulted in misses for pre-existing faults. Overall vibration deployed with knowledge of the International Organization for Standardization (ISO) 10186 alert standards has helped identify pre-existing conditions. Clarification of the failure modes detected by overall vibration has helped explain misses. Failure modes detected by overall vibration include imbalance, misalignment, looseness and late-stage bearing failure. Overall vibration is a direct measurement for detecting and monitoring imbalance, misalignment and looseness of rotating assets. The units for overall vibration are inches per second (ips)-peak, which is a velocity measure. Overall vibration is typically calculated from an acceleration reading measured using a $100 to $200 accelerometer. This ISO standard measurement has been around for decades. ISO 10816 defines how to measure and set alert thresholds. For example, the ISO 10816 standard calls for a 2-1000 hertz (Hz) frequency range and recommends alert levels for typical machines at 0.2, 0.5 and 1.0 ips-peak for minor, warning and critical alert levels. While overall vibration is excellent at detecting the presence and severity of imbalance, misalignment and looseness, many would argue it is not predictive and that overall vibration is a lagging indicator, as the problem or defect already exists. Yet, finding an imbalance or looseness defect when it is small has significant benefit if operations and maintenance have enough time to take the machine down to fix the problem while it is still small. It is best to repair the problem early, when it is a small cost, in comparison to waiting too long and fixing the problem when it has caused additional collateral damage. One example is waiting until the pump shaft is broken, versus aligning the motor, pump, and inlet and outlet piping.Condition Monitoring 3.0—Predictive Maintenance—2010s
IIoT measurements for predictive maintenance is much akin to the discussion around business key performance indicators (KPI)-leading versus lagging. The monitoring described earlier, although good, is still lagging or condition based. For some, predictive maintenance is synonymous with technologies such as:- infrared thermography (IR)
- ultrasonic
- partial discharge testing
- monthly vibration routes and analysis of vibration spectrum by trained and experienced professionals
Condition Monitoring 4.0—Industrial Artificial Intelligence—Current
The current advancement in predictive maintenance is to further automate the analysis process using artificial intelligence (AI) models. With the new and rich data stream from ultrasonic sensors, edge processing of the data and connectivity to the cloud, proven AI models have been developed that detect pre-existing conditions without the time, cost and frustration of baselining. Established AI models allow 90 percent or more of industrial assets to have alerts accurately established upon initial deployment. It also can amass the leading indicators mentioned above with sensors and connectivity, but also make the leap to automatic pattern detection driving quantitative patterns with various weak indicators or the specifics of the plant or line itself. The final step to realize success in any predictive maintenance program is to translate the alert or condition to a specific or “prescriptive” maintenance task. For this application, a second AI model is deployed that translates the alert or machine learning classification and severity to a prioritized maintenance task, which is then emailed or integrated with existing computerized management systems (CMMS) for planning, scheduling and managing maintenance work orders. This AI model relies on metadata about the asset type and context of its service criticality to establish the intelligent and prioritized work order. Using an application programming interface (API), the intelligence can be directed into existing systems, which limits any additional training. As a result, the catch phrase can be: "It is not rocket science, we're just automating the mundane tasks.” This frees human resources for higher-level thinking. The goal is to focus on the right work or assets and do fewer things with a higher standard by examining criticality and workflow.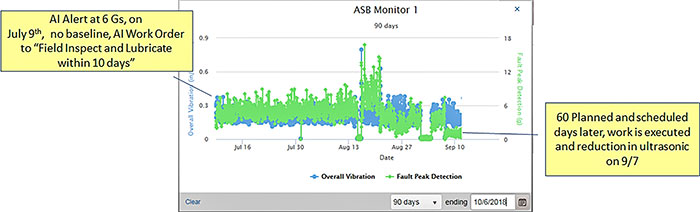
 Images 1 & 2. Sixty-day predictive maintenance on legacy equipment (Images courtesy of ATEK)
Images 1 & 2. Sixty-day predictive maintenance on legacy equipment (Images courtesy of ATEK)