
Pumps & Systems, April 2013
Editor’s note: The following article is based on a Pumps & Systems webinar presented by Mr. Kernan in October 2012. Readers can register for the presentation slides and audio under the “Webinars” section of www.pump-zone.com.
Industrial facilities have the same fundamental goals, no matter the product they manufacture or the market they serve. From top executives to the plant floor, a common goal is to cut costs while improving reliability and process control. A recent poll confirmed that energy efficiency and maintenance were the top two concerns of industrial pump users in 2012. From an investment perspective, focusing on these concerns makes sense. More than 50 percent of the life-cycle costs of a typical chemical pump are made up of energy, maintenance and repair costs (see Figure 1). But what is actually being done to address these concerns?
When pressure is applied to maintain the steady pace of plant operations, the approach to maintenance could fulfill Albert Einstein’s definition of insanity, “...doing the same thing over and over again and expecting different results.” Getting caught in “firefighting” mode is common—fixing critical assets that have failed and putting them back into production as quickly as possible, and then moving to the next piece of problematic equipment. However, with the abundance of data on rotating equipment that are readily available, operators can implement different pump maintenance strategies to mitigate risks and optimize budgets.
This article addresses how to achieve a balanced maintenance approach, illustrating the pitfalls of a “one-size-fits-all” mentality. It describes the spectrum of maintenance philosophies and gives applicable advice on how to improve the bottom-line benefits of total pump system investments..jpg)
Above: A South American copper mine implemented a condition-based maintenance system to monitor 16 pumps and motors at four remote locations. The system gives mine operators real-time data on all pumps and motors, allowing them to monitor vibration levels, temperatures and more.
Not All Industrial Equipment is Equal
Certain pieces of the process will have a greater impact on plant productivity. Although the boundaries are often blurred, the industrial equipment population can be broken down into four tiers: critical, essential, important and the remaining balance of the plant.
Smallest in volume, critical equipment failure can pose significant production losses and safety threats. Less important, balance-of-plant equipment generally represents more of the total assets, but failure will not result in substantial plant downtime. The balance-of-plant assets can quickly consume maintenance resources and budgets if not managed properly.
Before determining which maintenance philosophy to apply, end users should consider the equipment’s relative impact to the overall process and critically rank all assets. Four maintenance philosophies for consideration are:
- Reactive—Running a piece of equipment to failure and fixing it when it breaks
- Preventive—Time-based maintenance activities
- Predictive—Using condition-based data to help predict the likelihood of a failure
- Proactive (Precision)—Understanding why the failure occurred and implementing a change to prevent future failures
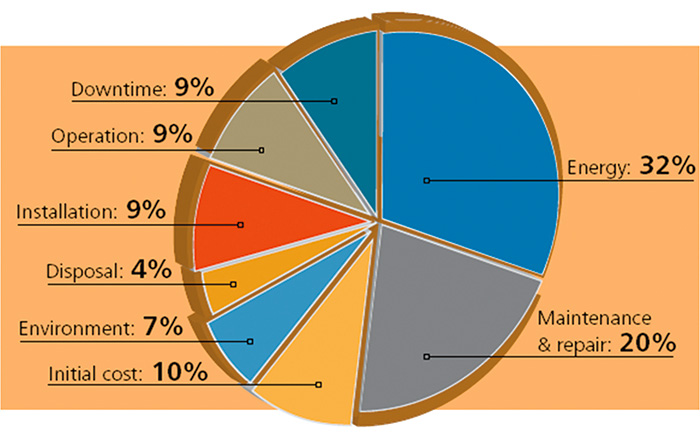
Figure 1. This breakdown of life-cycle costs highlights the importance of finding the right equipment for the right job. The combined cost of energy, along with maintenance and repair, makes up more than half the overall life-cycle cost for equipment. Cutting these costs down can lead to big savings. Source: Top 10 Global Chemical Manufacturer, FY 2006
Reactive Maintenance: Not Always Wrong
Practicing predictive or proactive maintenance wherever possible seems ideal. However, this may not be cost effective for all equipment. For instance, balance-of-plant equipment that has a smaller impact on profitability may not be worth as much of an investment to closely monitor as critical or essential equipment. Reactive maintenance—otherwise known as “fix it when it breaks” mode—may suffice in these cases.
The bottom line is that end users should consider the costs to fix or replace a particular asset when determining what they are willing to spend on respective maintenance efforts.
The Problem with
Preventive Maintenance
Under normal circumstances, one could assume that the probability of equipment failure increases with time. In the 1960s, this maintenance paradigm prevailed. After the initial burn-in phase in which a high likelihood of infant mortality exists, the probability of failure evens out, followed by an eventual increase in probability of failure near the end of life. For preventive maintenance, the thought process is simple: if repaired before end of life, catastrophic failure can be prevented.
However, a famous 1978 reliability-centered maintenance report from Nolan and Heap revealed that 89 percent of failures are random. The incline in failure probability over time is an oversimplification. In fact, performing invasive preventive maintenance actually introduces a new burn-in phase prematurely and can increase the probability of failure. So if not time, what factor can be used to determine the best schedule for maintenance activities?
Predictive Maintenance: Driven by Data
Fortunately, a benefit of rotating equipment like pumps is that they provide a signature of health. There are many opportunities to capture trendable and repeatable data, such as pressure, vibration and temperature. Performing predictive maintenance means using this data to end users’ advantage, keeping detailed records to capture baselines over time and then looking for overall increases that indicate a problem.
The integration of low-cost sensors directly on equipment is now becoming standard with OEM machines. There is also the wireless option, which is becoming more affordable and therefore practical to implement beyond only critical assets. The integration of mobile technology and the internet are making data accessible and actionable from anywhere in the world. As these technologies mature, the effort to shift from reactive to predictive is becoming much simpler and more affordable.
Decentralizing Expertise
When a small North American oil refinery experienced a fire at the bottom of a vacuum tower in 2008, the resulting three-day shutdown caused $1.5 million in damages and lost production.
The root cause of the problem was a failed mechanical seal on a relatively small, overhung, inline API-style pump. This incident severely impacted the bottom line and created a dangerous situation for the refinery personnel.
In late 2009, the oil refinery made the decision to implement a wireless continuous monitoring system. With this technology, a data monitor examines the process and mechanical side of the pump, taking readings on bearing vibration, bearing temperature, suction pressure, discharge pressure and motor amps.
The data monitor wirelessly connects to a communications module that feeds this information to two sources:
- Pump key performance indicators—such as pump discharge pressure, pump suction pressure and motor amps—are fed to the refinery’s control room for operators to track where the pump is running on the pump performance curve and whether it has adequate net positive suction head to prevent cavitation.
- Machine health data—such as tri-axial bearing vibration and bearing temperature—are sent to a Web-based condition monitoring platform, enabling the head reliability engineer to monitor the pump at all times, from any location, through the Internet or a mobile device.
The reliability engineer was able to track rapid upward trends with greater convenience, which helped catch a step change in the pump’s outboard bearing vibration.
The pump was shut down, and the bearings were replaced to prevent another catastrophic failure.
Since implementing a predictive continuous monitoring system, the pump has increased mean time between failures (MTBF) and avoided catastrophic failure. In addition, the facility reported no unplanned maintenance activities on this pump for more than three years.
Proactive Maintenance
While predictive maintenance uses data to help foresee equipment issues, proactive maintenance takes this philosophy one step further. Also referred to as “precision,” it requires an understanding of why a failure occurred and a commitment to implementing change to prevent future failures and increase the MTBF.
This depends heavily on participation from cross-functional teams because improving reliability is everyone’s job, from maintenance to management.
Practicing proactive pump maintenance does not always require exhaustive root-cause analysis. Start with basic questions, such as:
- Where is the pump operating on the curve with respect to best efficiency point (BEP)?
- Is the pump the right size for the application?
- Is cavitation evident?
- Does evidence of process upset conditions exist?
- Does the pump experience dry running?
- Is the pump run against a throttled or closed discharge?
- Is the mechanical seal and flush plan properly selected for the application?
By answering these questions, top targets for change will be identified. It starts with data integrity. Standardizing on a thorough set of failure codes is important. More important is setting and enforcing the policy to incorporate these codes into a computerized maintenance management system (CMMS).
When everyone is adamant about putting in fault codes that accurately describe the failure modes, bad actors are quickly identified. By proactively working through the bad actors, repeat maintenance activities caused by these machines can be eliminated, reducing costs and increasing productivity.
Driving Procedural Change
A 700-pump North American chemical plant was under extreme pressure to reduce pump maintenance costs and improve MTBF. Its plan was to embed a pump specialist as a full-time resource to transform the facility’s maintenance practices.
The first task was to reconcile the pump work order history because vague or generic failure codes made the data less useful. The specialist made procedural changes to ensure that the fault codes and job materials were correctly assigned in the CMMS for future trending.
With better data, the specialist created a “hot list” of pumps to target for root cause analyses. Cross-functional teams were formed from maintenance, operations and pump and seal OEMs to address problems.
A plan was constructed to proactively work through the list at a rate of 10 per year.
The solutions applied were relatively simple:
- Trimming the impellers on oversized pumps
- Changing flush plans to ensure that sure seals were flushed properly and had cool operating environments
- Installing variable speed drives where appropriate
- In some cases, upgrading or replacing pumps to ensure they that had the right design for the job
While the solutions were simple, the results were powerful. In five years, pump MTBF increased by 108 percent. Annual operating costs per pump were reduced by 48 percent, saving the company more than $1.3 million per year.
Striking the Right Balance
In the world of industrial equipment, no two operations are the same. Since unplanned repairs can be 10 times as costly as scheduled maintenance, finding the right fit for each application—which may include taking a multifaceted approach—is important.
Consider a South American copper mine in which four pumping stations transported 16 million gallons of seawater 144 kilometers to its desert location every day.
Pump MTBF was low and mine operators were practicing firefighting maintenance—fixing failed equipment and putting it back into production as quickly as possible. The copper mine implemented both proactive and predictive maintenance strategies.
From a proactive standpoint, adjustments to check valves and control valves were made to slow response times, and pump starting and stopping procedures were implemented that helped mitigate water hammer effects.
The addition of a wireless condition monitoring system allowed maintenance to be predictive with the ability to monitor 16 pumps and motors at four remote locations over a span of 144 kilometers. The results included higher MTBF for the seawater pumping system and a 22 percent increase in annual production.
No matter the strategy or mix of strategies selected for industrial equipment maintenance, being aware of and responsive to data is key. Only when failures are fully understood and bad actors are targeted can meaningful change be effectively implemented. This requires being open and committed to change and following the path to improving reliability and optimizing maintenance budgets. P&S
